System and agents
3.10 Goal-based agents
So far, the examples of agent models we were looking at were not themselves calculating a way to achieve the purpose of their existence. The hoover robot we were discussing ends up cleaning the room, but its actions are simplistic; it doesn't have a concept of a goal or a target in its engine. We just designed it in a way so it will eventually end up cleaning the room. However, in more complex situations, agent programs have to possess a target or goal.
An autonomous car at a given time has several options it can take. For example, movement in different directions, acceleration or waiting in one place. The correct decision depends on the notion of a goal it was provided. When designing complex agents, it is desirable for the agent program to focus on reaching its target, rather than just designing the program to happen to complete its task eventually. Agents attempting to reach a predefined goal are goal-based agents.
It could be that the goal can be reached by a single action taken by the agent. This can be when we employ an agent function to control a large number of simple actuators that could not simultaneously be overseen by a human. However, the agent has to complete a series of actions to reach its pre-defined goal. There are two subfields of AI focussed on finding action sequences leading to the goal of the agent, referred to as search and planning methods.
Consider a simplified version of an autonomous vehicle. It has been given a map with roads connecting points like junctions. It wants to travel from a particular junction of roads to another. How could the agent program find a particular path or the shortest path to the target? One approach to this program would be for the agent to consider what states taking a specific action sequence can lead it to taking specific roads in this case. Then it can explore the graph of different states it can reach in the hope of finding the goal amongst them. This approach is normally referred to as searching, as the agent is indeed searching for the goal amongst the possible action sequences.
However, this model of autonomous driving was oversimplified. In practice, the agent program has to control numerous different actuators such as for accelerating, turning, shifting gears and even adjusting air-conditioning. Therefore, exploring what states taking a specific set of actions may put the agent in is computationally expensive. Instead, the agent will identify more abstract states and actions, such as 'move(a,b)'. It will define this action taking the agent from junction 'a' to 'b', including all the possible sub-actions it must complete with its actuators to achieve this. Then it can explore states more abstractly, such as 'location(a)' representing the state where the vehicle is located at 'a' or 'street(a,b)', representing the existence of a path between those locations. Actions will require certain statements to hold and affect them, in our toy example: move(a,b) requires location(a) and street (a,b) to hold, and turns location(a) into location(b). This way, the agent program can turn complex tasks into a system of conditions and actions which can be explored through specialised algorithms. This approach of finding the goal state is referred to as planning.
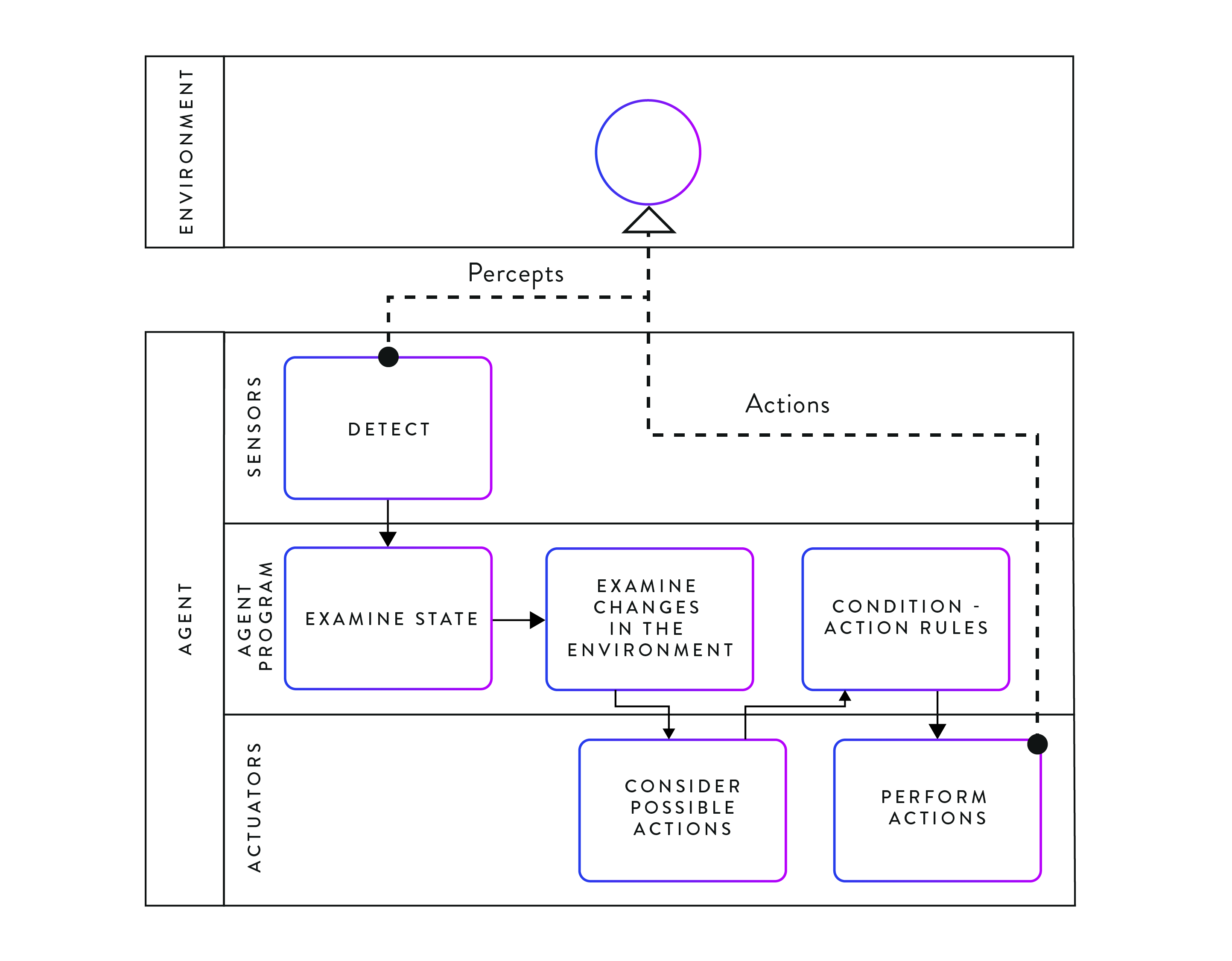
Figure 3. A goal-based agent as described using BPMN. Building on the model-based reflex agent, this type of agent additionally considers the impact of its possible actions before actually performing the actions.